随着容器化应用的广泛应用,Kubernetes 成为了管理和编排这些容器的首选平台。对于资源受限的生产环境和边缘部署来说,K3s 是一个理想的轻量级 Kubernetes 发行版。然而,为了确保 K3s 集群的稳定性和性能,监控是至关重要的。本文将介绍如何通过 kube-prometheus-stack 工具来监控 K3s 集群,以便有效地监控 K3s 集群的运行状态。
先决条件
K3s 集群
你必须拥有一个健康的 Rancher K3s 集群。本次示例,将安装两个节点的 K3s 集群:一个 K3s master 节点,一个 K3s worker 节点,并且集群采用嵌入式 etcd 作为数据存储。
本文使用的 K3s 版本为:v1.27.6+k3s1

Helm
如果你尚未安装 Helm3,请参考 Helm 官网文档安装 Helm。
Kubernetes Storage Class
为了支持集群中任何节点上的监控组件的持久化和调度,你需要提供 Kubernetes Storage Class。
你可以使用像 Longhorn 这样成熟的集群存储解决方案。但为了方便演示,本文使用 K3s 自带的 Local Path Provisioner。
K3s 集群准备
默认情况下,K3s 将其多个管理组件绑定到节点主机的 localhost 127.0.0.1 地址,具体为:Kube Controller Manager、Kube Proxy 和 Kube Scheduler。
但是,为了进行监控,我们需要公开这些 endpoint,以便 Prometheus 可以提取它们的指标。因此,我们需要在 0.0.0.0 地址上公开这些组件的 metrics。
你可以通过将包含以下内容的文件放置在 “/etc/rancher/k3s/config.yaml” 中来更改 K3s master 节点上的这些设置。
# /etc/rancher/k3s/config.yaml
kube-controller-manager-arg:
- "bind-address=0.0.0.0"
kube-proxy-arg:
- "metrics-bind-address=0.0.0.0"
kube-scheduler-arg:
- "bind-address=0.0.0.0"
# 公开 etcd metrics
etcd-expose-metrics: true
另外,K3s worker 节点上也运行了 Kube Proxy 组件,所以也需要在 K3s worker 节点的 “/etc/rancher/k3s/config.yaml” 中添加如下配置:
# /etc/rancher/k3s/config.yaml
kube-proxy-arg:
- "metrics-bind-address=0.0.0.0"
安装 K3s 集群
K3s master 节点
- 配置 K3s master(IP:172.31.38.19)
root@ip-172-31-38-19:~# mkdir -p /etc/rancher/k3s/
root@ip-172-31-38-19:~# cat >/etc/rancher/k3s/config.yaml <<EOL
# /etc/rancher/k3s/config.yaml
kube-controller-manager-arg:
- "bind-address=0.0.0.0"
kube-proxy-arg:
- "metrics-bind-address=0.0.0.0"
kube-scheduler-arg:
- "bind-address=0.0.0.0"
# 公开 etcd metrics
etcd-expose-metrics: true
EOL
- 安装 K3s master
root@ip-172-31-38-19:~# curl -sfL https://get.k3s.io | K3S_TOKEN=SECRET sh -s - server --cluster-init
K3s worker 节点
- 配置 K3s worker(IP:172.31.41.39)
root@ip-172-31-41-39:~# mkdir -p /etc/rancher/k3s/
root@ip-172-31-41-39:~# cat >/etc/rancher/k3s/config.yaml <<EOL
# /etc/rancher/k3s/config.yaml
kube-proxy-arg:
- "metrics-bind-address=0.0.0.0"
EOL
- 安装 K3s worker
root@ip-172-31-41-39:~# curl -sfL https://get.k3s.io | K3S_TOKEN=SECRET sh -s - agent --server https://<ip or hostname of server>:6443
现在,每个服务都有可用的侦听器,Prometheus 就可以抓取这些 metrics
# kubeControllerManager port: 10257
# kubeScheduler port: 10259
# kubeProxy port: 10249
root@ip-172-31-38-19:~# ss -lntp | grep -E "10257|10259|10249"
LISTEN 0 4096 *:10249 *:* users:(("k3s-server",pid=3504,fd=203))
LISTEN 0 4096 *:10259 *:* users:(("k3s-server",pid=3504,fd=201))
LISTEN 0 4096 *:10257 *:* users:(("k3s-server",pid=3504,fd=178))
修改 Traefik Metrics 端口
K3s 使用 Traefik 作为开箱即用的 Ingress 控制器,在启动 K3s 时默认部署。默认配置文件位于 /var/lib/rancher/k3s/server/manifests/traefik.yaml,Traefik 默认的 metrics 端口为 9100,并且使用 HostPort 启动,这样就和 node-exporter 的 9100 端口冲突,所以我们需要提前修改 Traefik 的 metrics 端口。
要修改 Traefik 的配置信息,不要手动编辑 traefik.yaml 文件,因为 K3s 会在启动时使用默认值替换该文件。相反,你需要通过在 /var/lib/rancher/k3s/server/manifests 中创建 HelmChartConfig 清单来自定义 Traefik。有关更多详细信息和示例,请参阅使用 HelmChartConfig 自定义打包组件。有关配置 traefik 配置的更多信息,请参阅官方 Traefik Helm 配置参数。
## 本示例将 traefik 的 metrics 端口修改为 9900
root@ip-172-31-38-19:~# cat >/var/lib/rancher/k3s/server/manifests/traefik-config.yaml <<EOL
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: traefik
namespace: kube-system
spec:
valuesContent: |-
ports:
metrics:
port: 9900
exposedPort: 9900
EOL
Helm 自定义 values.yaml 文件
在使用 Helm 安装 kube-prometheus-stack 之前,我们需要创建一个自定义 values.yam 文件来调整 K3s 集群的默认 chart 配置。
覆盖管理组件配置
我们放在 K3s master 节点 (172.31.38.19) 上的 config.yaml 文件中公开了 Kube Controller Manager、Kube Proxy 和 Kube Scheduler 上的 metrics,并且在 K3s worker 节点上公开了 Kube Proxy 的 metrics。所以需要在 values.yaml 中指定对应的 endpoints 和 port。如果没有这些显式的设置,kube-prometheus-stack 将无法找到这些 metrics。
endpoints是一个数组,因此如果你有 3 个 HA master 节点,则需要指定所有 3 个 IP 地址。 以下配置中,其实只设置endpoints即可,其他参数均为默认值,加上这些配置值是为了更详细的说明配置项。
kubeControllerManager:
enabled: true
endpoints:
- 172.31.38.19
service:
enabled: true
port: 10257
targetPort: 10257
serviceMonitor:
enabled: true
https: false
kubeScheduler:
enabled: true
endpoints:
- 172.31.38.19
service:
enabled: true
port: 10259
targetPort: 10259
serviceMonitor:
enabled: true
https: false
kubeProxy:
enabled: true
endpoints:
- 172.31.38.19
- 172.31.41.39
service:
enabled: true
port: 10249
targetPort: 10249
覆盖 ETCD 配置
kubeEtcd:
enabled: true
endpoints:
- 172.31.38.19
持久化存储
生产环境请务必为 AlertManager、Grafana 和 Prometheus 使用外部存储。如果不这样做,将使用一个 emptyDir,该目录仅在 Pod 生命周期内有效。
即使使用 K3s local-path storage class 也只能提供节点级别的持久化。本文为了方便演示,使用的是 local-path。生产环境建议使用像 Longhorn 这样成熟的集群存储解决方案。
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
prometheus:
prometheusSpec:
storageSpec:
## Using PersistentVolumeClaim
##
volumeClaimTemplate:
spec:
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
grafana:
persistence:
type: pvc
enabled: true
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
size: 1024Mi
完整的 values.yaml 文件
我在 github 中有一个监控 K3s 集群的完整示例 values.yaml 文件。这个示例 values.yaml 文件中包含了 Ingress 和 公开 AlertManager、Grafana 和 Prometheus 的设置,还有一些关于 AlertManager 的告警配置信息,但这些设置并非特定于 K3s。
这个示例中也包含了 监控 traefik 的 prometheus 配置,如果大家有需求,也可以参考。
Helm 安装 kube-prometheus-stack
# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# helm repo update
# kubectl create namespace monitoring
# helm install prometheus-community prometheus-community/kube-prometheus-stack --namespace monitoring -f values.yaml
如果你修改 values.yaml 文件并需要更新版本,请将 install 更改为 upgrade。
# helm -n monitoring upgrade prometheus-community prometheus-community/kube-prometheus-stack -f values.yaml
验证安装状态:
# 列出所有 namespace 中的 releases
helm list -A
# 列出 monitoring namespace 中的 releases
helm list -n monitoring
# 检查 prometheus stack release 状态
helm status prometheus-community -n monitoring
安装完成后,我们就可以访问 Prometheus、Alertmanager、Grafana 的 UI 来查看 K3s 集群的状态:
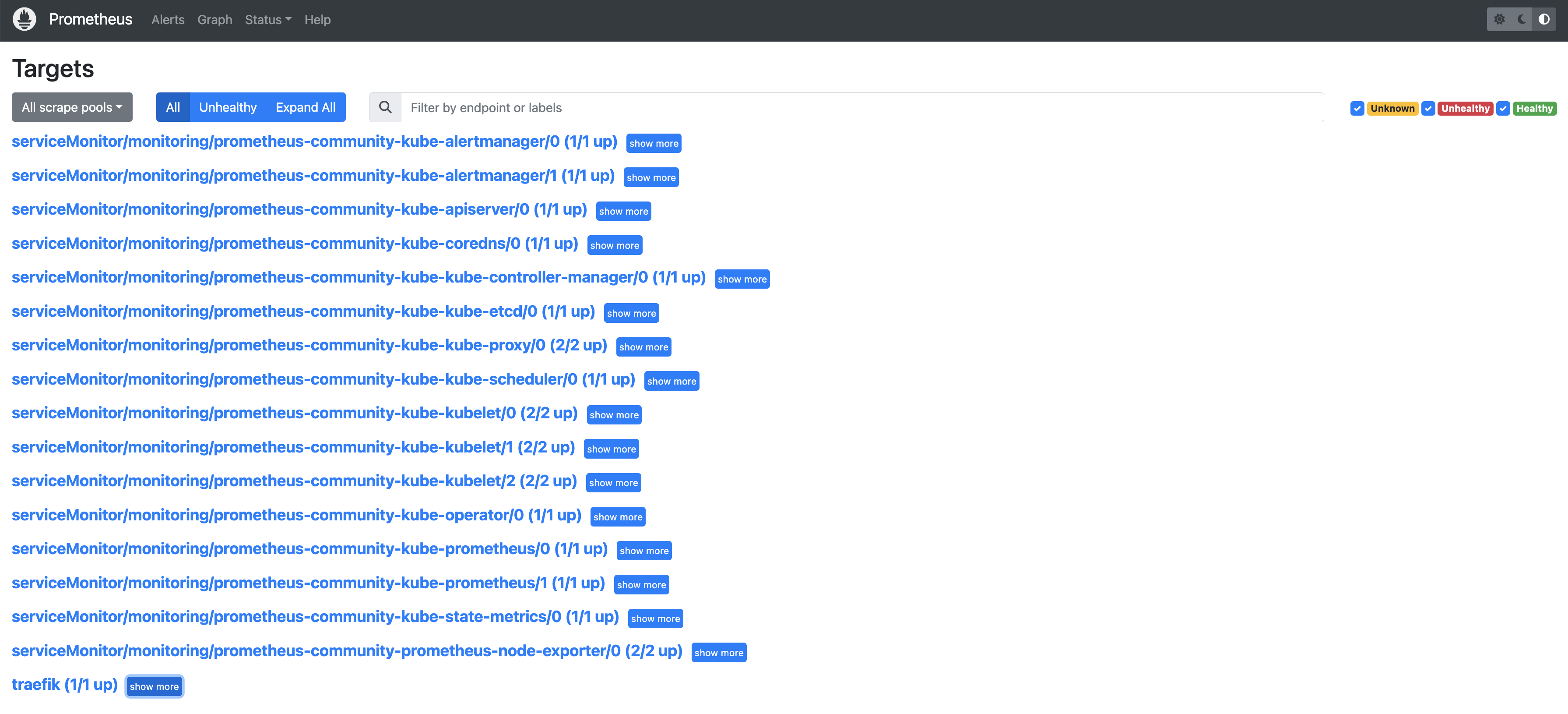
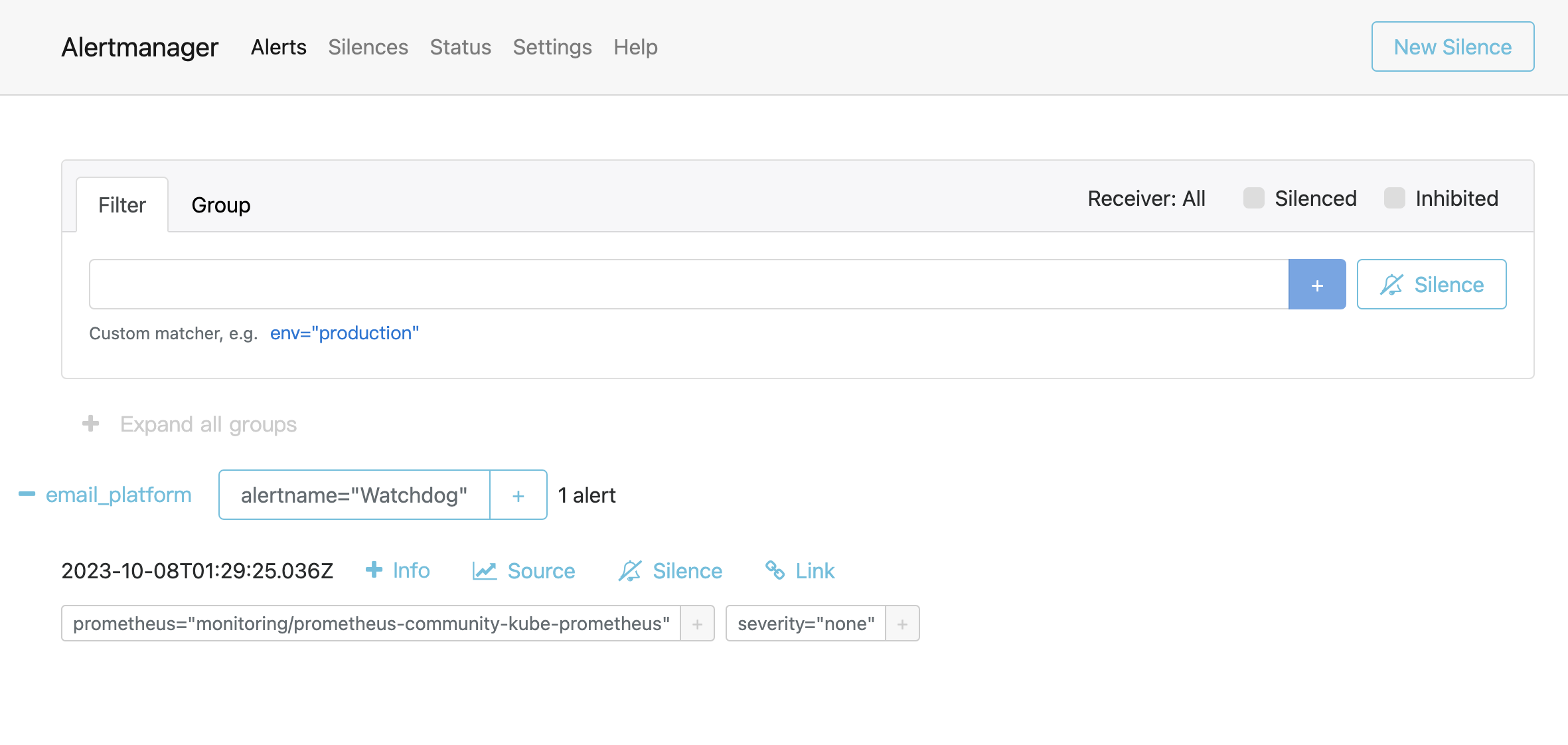
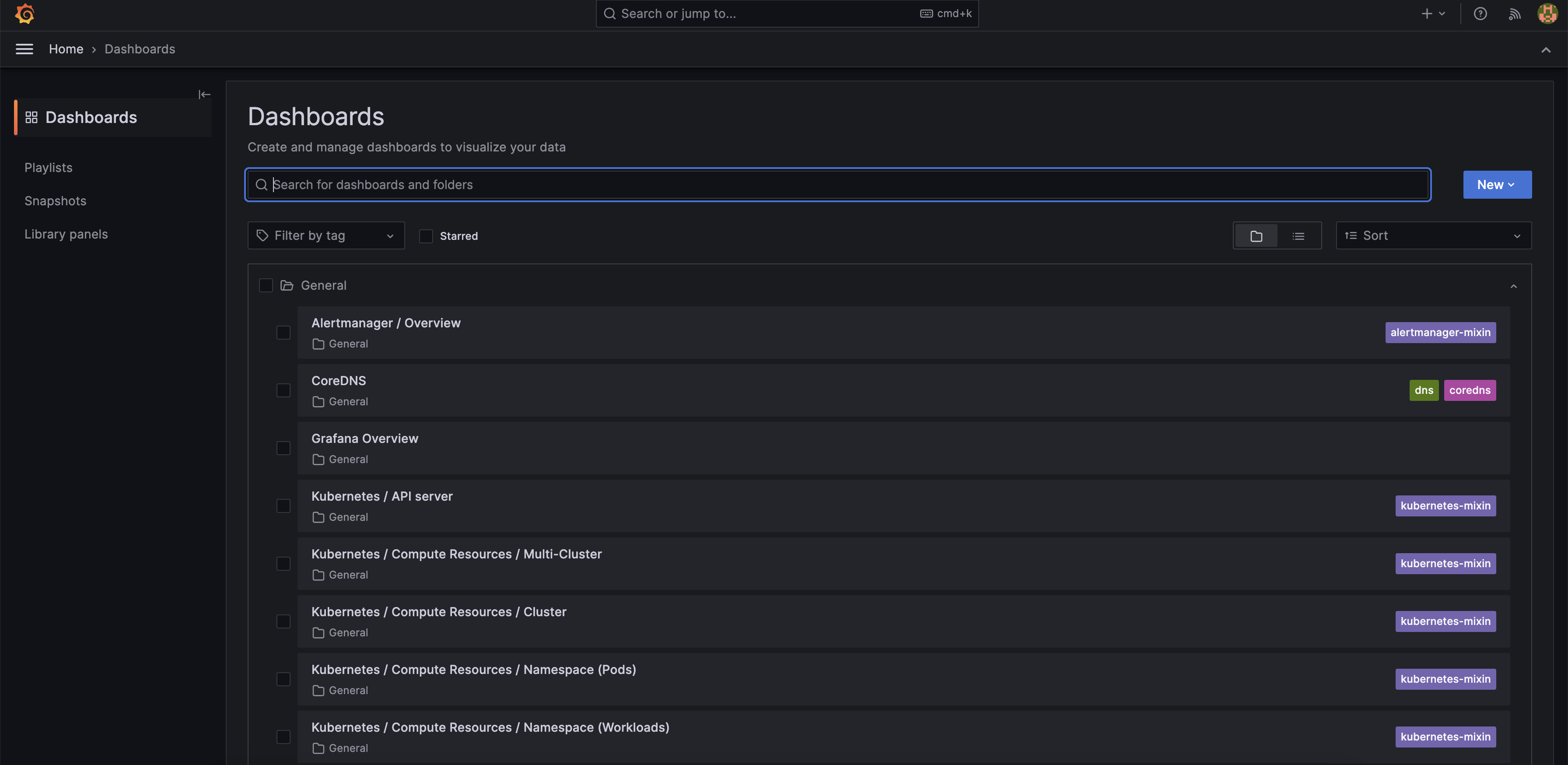
总结
通过本文中的步骤,你可以轻松地使用 kube-prometheus-stack 监控 K3s 集群,确保其稳定性和性能。监控是运维工作中的重要一环,帮助你及时发现和解决潜在问题,提高集群的可用性和效率。借助 Prometheus、Alertmanager 和 Grafana,你可以创建交互式仪表板和可视化,深入了解集群的运行状况,为你的应用程序提供更好的支持和管理。希望本文对你有所帮助,让你更好地运维和管理 K3s 集群。